AI Basic Notes
Linear Algebra
Linear Space
向量空间的一组基: 张成 (span) 该空间的一个线性无关 (linearly independent) 向量集.
Linear Transformation
线性变换是指一个向量空间到另一个向量空间的映射, 满足加法和数乘运算的线性性质:
左乘矩阵相当于对列向量进行线性变换, 右乘矩阵相当于对行向量进行线性变换.
表示 n 维空间到 m 维空间的线性变换:
- n 列: 输入空间有 n 个基向量, 即为 n 维空间.
- m 行: 输出空间每个基向量对应 m 个坐标, 即为 m 维空间.
- 表示 n 维空间到一维空间的线性变换: 向量点乘 (Dot Product) 可以理解为 通过 变换到一维空间后的投影.
- Dot Product: .
- Cross Product: .
- , .
Basis changes, translating transformations:
Determinant
表示矩阵 A 的行列式, 表示该变换对空间的缩放因子:

时, 表示该变换将空间压缩到一个低维空间, 称矩阵 为奇异矩阵 (Singular Matrix):
- 矩阵 列向量线性相关.
- 矩阵 不满秩 (Not full rank).
- 矩阵 不可逆.
Determinant for 2d matrix:

Determinant for 3d matrix:
Determinant for matrix multiplication:
Gaussian Elimination
高斯消元法求解线性方程组 (Linear System Of Equations):
首先第一行的第一个元素化为 1, 下面每行减去第一行乘以该行第一个元素的倍数, 从而把第一列除第一行外的全部元素都化为 0, 进而把第二列除前两个元素之外的元素都化为 0, 最后把矩阵化为上三角矩阵. 类似地, 从最后一行开始, 逐行把上三角矩阵化为单位矩阵.
Eigenvalue and Eigenvector
eigenvalue quick calculation:
Linear Algebra Reference
- Interactive book: impressive linear algebra.
Mathematical Analysis
Limit
洛必达法则是求解分数形式的未定型极限 的有效方法之一:
Derivative
常见导数:
Series
泰勒级数利用函数在某点的各阶导数, 近似该点附近函数的值:
Euler's Formula
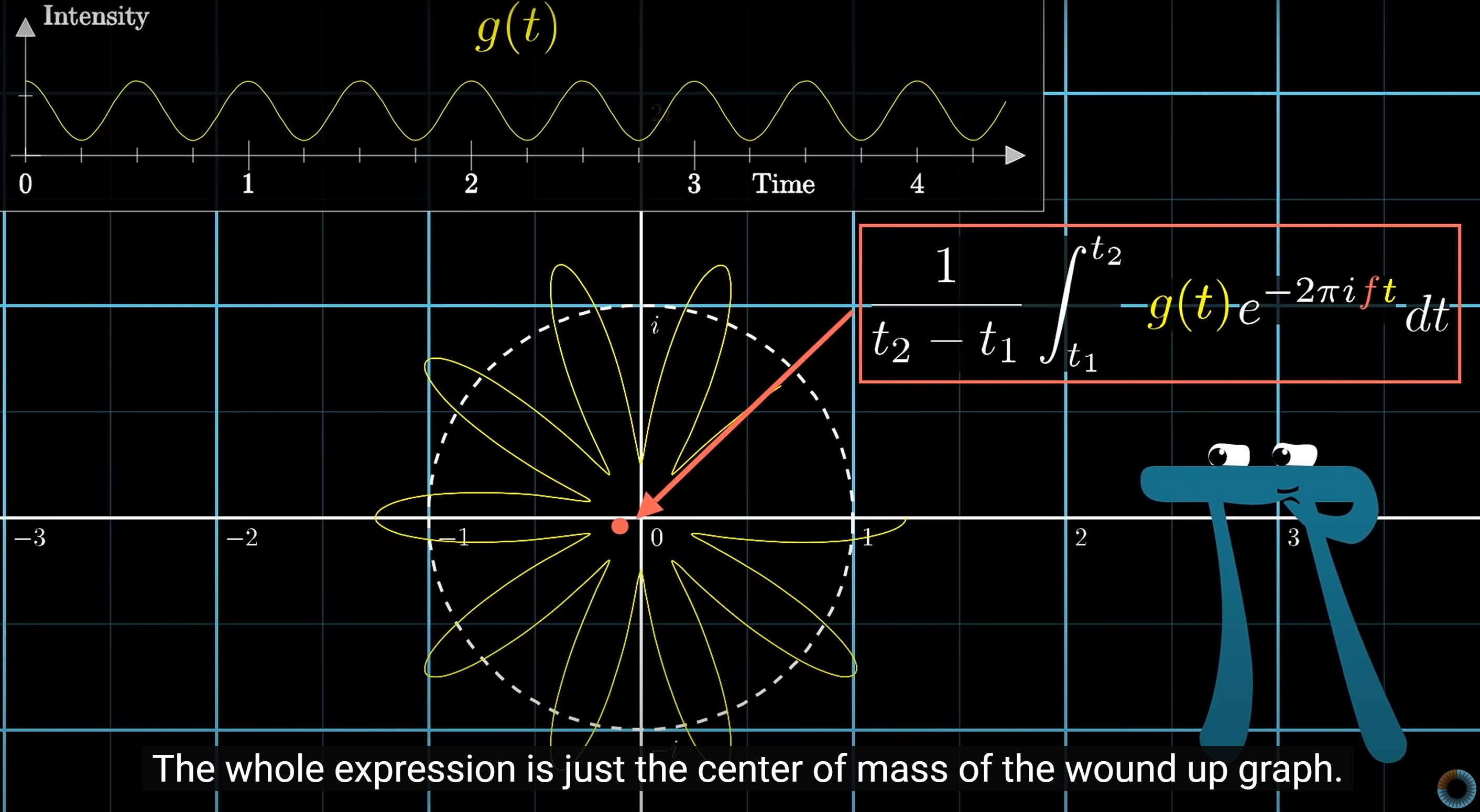
复数平面 (Complex Plane) 上的圆周运动:
Fourier Transform
Time to frequency transform:
Discrete Fourier Transform (DFT):
outcomes
Differential Equation
微分方程 (Differential Equation) 是描述变量之间关系的方程, 通常包含未知函数及其导数, 用于描述物理现象和自然规律.
First Order Differential Equation
一阶微分方程:
Second Order Differential Equation
Gravitational force equation:
Partial Differential Equation
Black-Scholes / Merton equation:
Phase Space
相空间是描述系统状态的空间, 每个点代表系统的一个状态, 点的轨迹描述了系统的演化.
import numpy as np
# Physical constants
g = 9.8
L = 2
mu = 0.1
THETA_0 = np.pi / 3 # 60 degrees
THETA_DOT_0 = 0 # No initial angular velocity
# Definition of ODE
def get_theta_double_dot(theta, theta_dot):
return -mu * theta_dot - (g / L) * np.sin(theta)
# Solution to the differential equation (numerically)
def theta(t):
theta = THETA_0
theta_dot = THETA_DOT_0
delta_t = 0.01 # Time step
for _ in np.arange(0, t, delta_t):
theta_double_dot = get_theta_double_dot(theta, theta_dot)
theta += theta_dot * delta_t
theta_dot += theta_double_dot * delta_t
return theta
Mathematical Statistics
Normal Distribution
若随机变量 服从一个位置参数为 , 尺度参数为 的概率分布, 且其概率密度函数 (Probability Density Function, PDF) 为:
则这个随机变量称为正态随机变量, 正态随机变量服从的分布称为正态分布, 记作 , 读作 服从 (正态分布). 其中 为均值 (数学期望 Mean), 为标准差 (Standard Deviation).
正态分布 (又称 Gaussian Distribution) 是一种连续概率分布. 当 为 0, 为 1 时, 称为标准正态分布 (Standard Normal Distribution).
Central Limit Theorem
在自然界与生产中, 一些现象受到许多相互独立的随机因素的影响, 如果每个因素所产生的影响都很微小时, 总影响 (Sum) 可以看作服从正态分布.
相互独立的正态分布, 其和也是正态分布. 总体正态分布的均值等于各个分布的均值之和, . 假设协方差为 0, 则总体正态分布的方差等于各个分布的方差之和, , 可以得到总体正态分布的标准差为 .
设随机变量 独立同分布(Independent Identically Distribution), 且均值为 , 方差为 , 对于任意 , 其分布函数为
满足
独立同分布的中心极限定理说明, 当 足够大时, 随机变量 近似服从正态分布 ; 标准化后的随机变量 近似服从标准正态分布 .
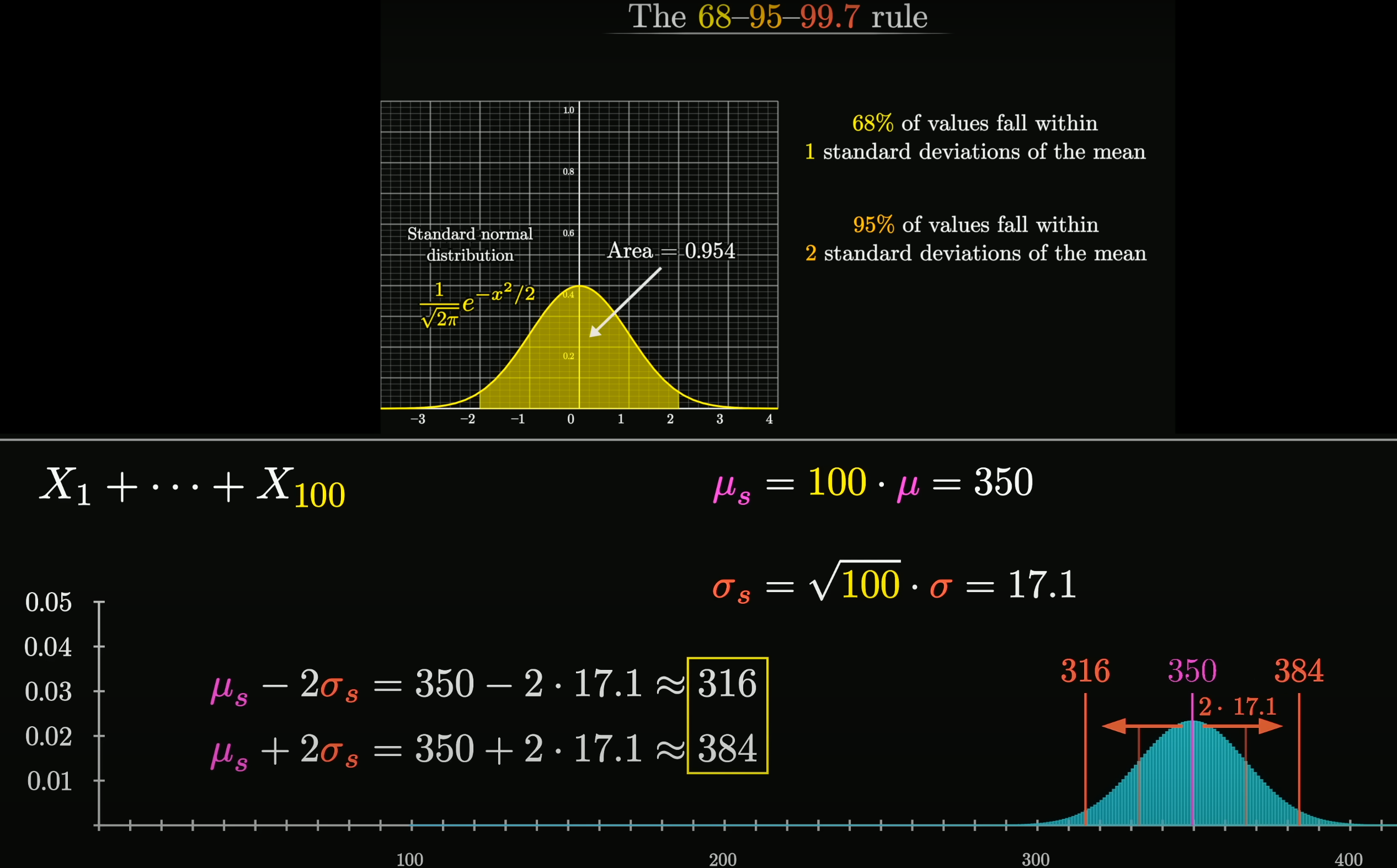
更一般化的中心极限定理, 可参见林德伯格中心极限定理 (Lindeberg CLT) etc.
Gaussian Integral
高维空间求解高斯积分:
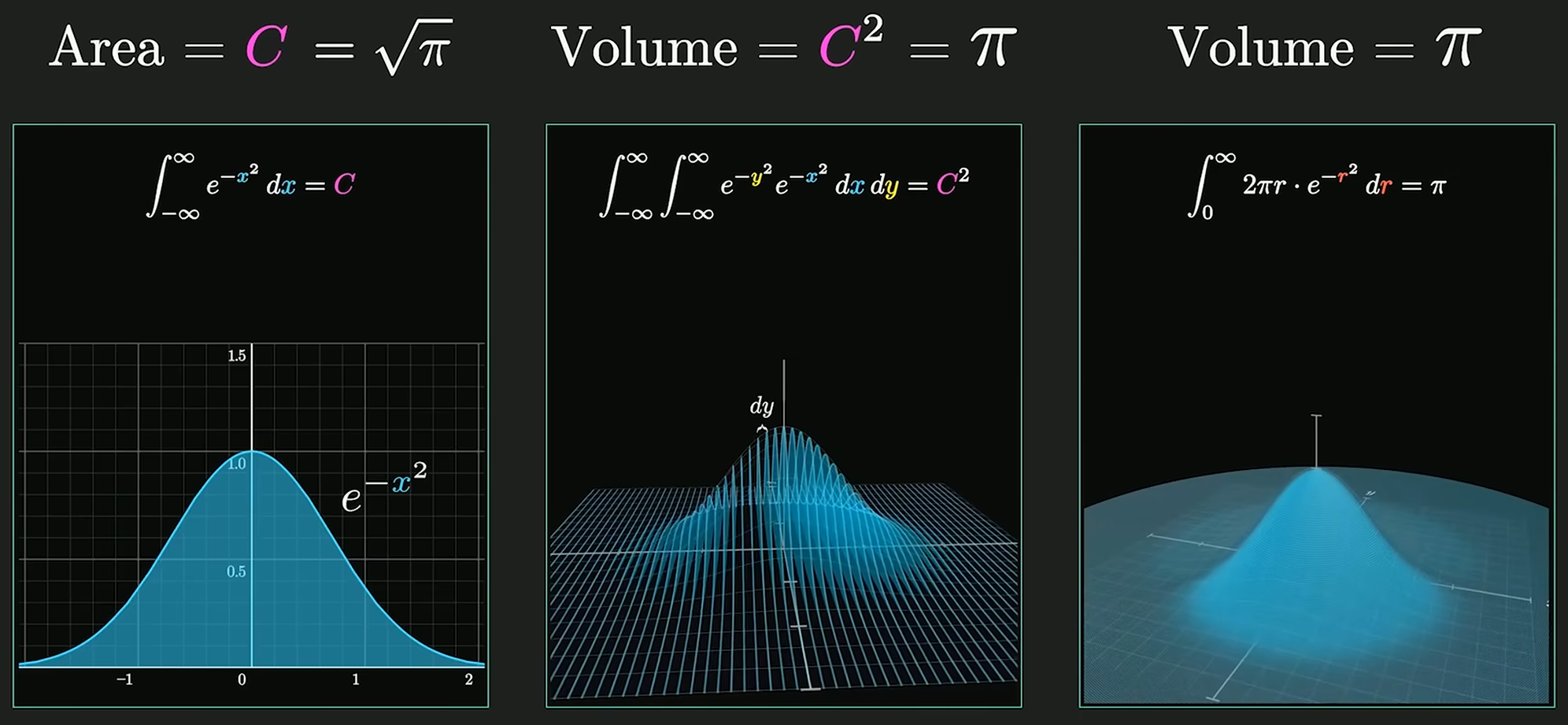
对于正态分布, 系数 使得概率密度函数的积分为 1, 即 , 使其成为有意义的概率分布.
Binomial Distribution
重复 n 次独立的伯努利试验, , 期望值 , 方差 :
Bayes Theorem

其中, 称为贝叶斯系数 (Bayes Factor):
Information Entropy
信息熵 是对信息量的度量 (), 概率小的事件发生所带来的信息量大, 概率大的事件发生所带来的信息量小, 即概率小, 出现机会小, 不确定性大, 信息熵大, 信息量大:
Supervised Learning
Regression
Output a scalar:
- Linear regression: , .
- Polynomial regression: .
- Logistic regression (output probability): , .
If model can't even fit training data, then model have large bias (underfitting). If model can fit training data but not testing data, then model have large variance (overfitting).
Underfitting
To prevent underfitting, we can:
- Add more features as input.
- Use more complex and flexible model.
Overfitting
More complex model does not always lead to better performance on testing data or new data.
| Model | Training Error | Testing Error |
|---|---|---|
| 31.9 | 35.0 | |
| 15.4 | 18.4 | |
| 15.3 | 18.1 | |
| 14.9 | 28.2 | |
| 12.8 | 232.1 |
A extreme example, such function obtains training loss, but large testing loss:
To prevent overfitting, we can:
- More training data.
- Data augmentation: crop, flip, rotate, cutout, mixup.
- Constrained model:
- Less parameters, sharing parameters.
- Less features.
- Early stopping.
- Dropout.
- Regularization.
Classification
- Binary classification: , , e.g spam filtering.
- Multi-class classification: , , e.g document classification.
- Non-linear model:
- Deep learning: , e.g image recognition, game playing.
- Support vector machine (SVM): .
- Decision tree: .
- K-nearest neighbors (KNN): .
Structured Learning
Training
Find a function :
evaluates how well fits (object compatible).
Inference
Given an object :

- Evaluation: what does look like.
- Inference: how to solve problem.
- Training: how to find with given training data.
Structured Linear Model
Unsupervised Learning
Principal Component Analysis
主成分分析 (PCA) 是一种常用的数据降维方法, 将 个 维向量降为 维, 其目标是选择 个单位 (模为 ) 正交基, 使得原始数据变换到这组基上后, 各字段两两间协方差为 (各字段完全独立), 各字段的方差尽可能大 (各字段降维后分布尽可能分散), 即在正交的约束下, 取最大的 个方差:
协方差矩阵 是一个对称矩阵, 其对角线分别为各字段的方差, 其第 行 列和第 行 列元素相同, 表示 和 两个字段的协方差. 将协方差矩阵对角化, 得到基于矩阵运算的 PCA 算法如下:
- 将原始数据按列组成 行 列矩阵 .
- 将 的每一行 (代表一个属性字段) 进行零均值化, 即减去这一行的均值, 使得 , 方便方差与协方差的计算.
- 求出协方差矩阵 的特征值及对应的特征向量.
- 将特征向量按对应特征值大小从上到下按行排列成矩阵, 取前 行组成矩阵 .
- 即为降维到 维后的数据.
Word Embedding
词嵌入是自然语言处理 (NLP) 中的一种技术, 将词汇映射到实数向量空间, 使得词汇之间的语义关系可以通过向量空间中的距离来表示.
Variational Auto-Encoders
变分自编码器 (VAEs) 是一种生成模型, 通过学习数据的潜在分布来生成新的数据:
变分自动编码器学习的是隐变量 (特征) 的概率分布, , 通过深度网络来学习 的参数, 一步步优化 使其与 十分相似, 便可用它来对复杂的分布进行近似的推理:
- Feature disentangle: voice conversion.
- Discrete representation: unsupervised classification, unsupervised summarization.
- Anomaly detection: face detection, fraud detection, disease detection, network intrusion detection.
- Compression and decompression.
- Generator.

Generative Adversarial Networks
生成对抗网络 (GANs) 由两个网络组成: 生成器 (Generator) 和判别器 (Discriminator). 生成器的目标是生成尽可能逼真的数据, 判别器的目标是尽可能准确地区分真实数据和生成数据. 两个网络相互对抗, 生成器生成数据 (decoder in VAE), 判别器判断数据真伪 ( classification neural network), 生成器根据判别器的判断结果调整生成数据的策略, 不断提升生成数据的逼真程度.

Self-supervised Learning
Pre-trained models + fine-tuning (downstream tasks):
- Cross lingual.
- Cross discipline.
- Pre-training with artificial data.
- Long context window.
Pre-trained Models
Pre-trained Data
- Content filtering: 去除有害内容.
- Text extraction: 去除 HTML 标签.
- Quality filtering: 去除低质量内容.
- Document deduplication: 去除重复内容.
BERT
BERT (Bidirectional Encoder Representations from Transformers) 是一种 Encoder-only 预训练模型, 通过大规模无监督学习, 学习文本的语义信息, 用于下游任务的微调:
- Masked token prediction: 随机遮挡输入文本中的一些词, 预测被遮挡的词.
- Next sentence prediction: 预测两个句子的顺序关系.

GPT
GPT (Generative Pre-trained Transformers) 是一种 Decoder-only 预训练模型.
Fine-tuning
BERT Adapters
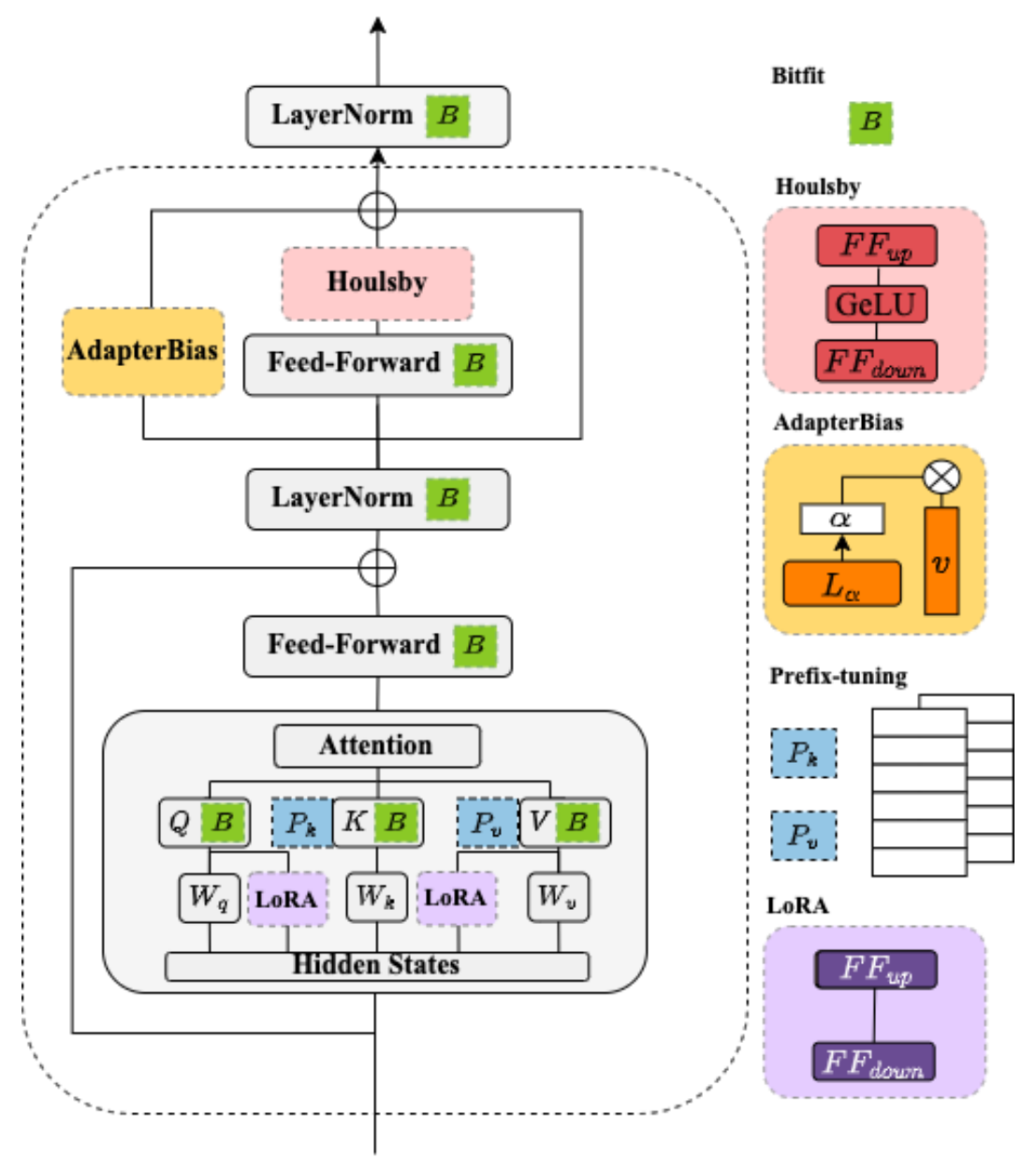
Low-Rank Adaptation
低秩适配 (LoRA) 是一种参数高效微调技术 (Parameter-efficient Fine-tuning), 其基本思想是冻结原始矩阵 , 通过低秩分解矩阵 和 来近似参数更新矩阵 , 其中 是减小后的秩:
在微调期间, 原始的矩阵参数 不会被更新, 低秩分解矩阵 和 则是可训练参数用于适配下游任务. LoRA 微调在保证模型效果的同时, 能够显著降低模型训练的成本.
Instruction-tuning
Make model can understand human instructions not appear in training data:
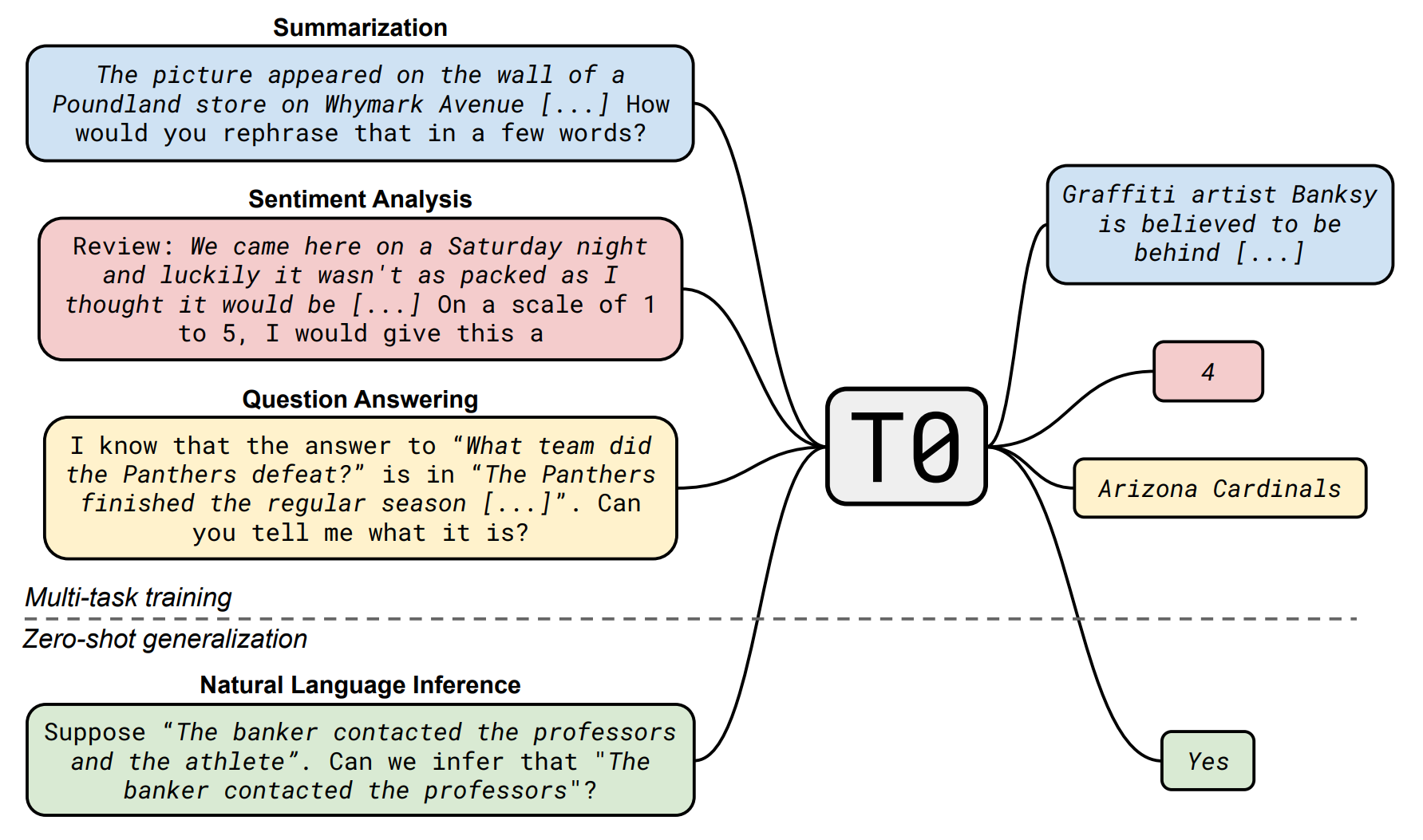
- 提高指令复杂性和多样性能够促进模型性能的提升.
- 更大的参数规模有助于提升模型的指令遵循能力.
Reinforcement Learning
强化学习是一种机器学习方法, 通过智能体与环境交互, 智能体根据环境的反馈调整策略, 利用梯度上升算法 (Gradient Ascent), 最大化长期奖励 (learn from rewards and mistakes).

Actor-Critic Model

Inverse Reinforcement Learning

Multilayer Perceptron

多层感知机是一种前馈神经网络 (Feedforward Neural Network) 就像是一个模拟大脑处理信息的过程, 通过多层处理 (输入层, 隐藏层, 输出层), 从原始数据中提取特征, 并做出预测或分类, 它通过调整内部连接权重来学习和改进其预测能力.
Linear Mapping
线性变换 :
- (
weight): 第 层第 个节点与上一层第 个节点连接的权重. - (
bias): 第 层第 个节点的偏置.
Activation Function
激活函数 , :
- 引入非线性特性, 使得网络可以学习和拟合复杂函数.
- ReLU (Rectified Linear Unit, 线性整流单元): , 可以解决梯度消失问题 (越靠近输入层的神经元梯度越接近 0), 加速收敛.
- Sigmoid: .
- e.g 归一化函数, 使得输出值在 0 到 1 之间, 可以使得整个网络成为概率模型.

Loss Function
损失函数 :
- 用于衡量真实值(或人工标注值) 与模型预测值 之间的差异.
- 常见的损失函数有均方误差 (Mean Squared Error, MSE) 和交叉熵 (Cross Entropy).
- 均方误差: .
- 交叉熵: , 常用于 classification 任务.
- Selective synaptic plasticity: .
is the size of hypothesis space, larger means deeper model:

Deep model need less neurons (parameters) to represent same function, means deep model has smaller , flat/shallow model has larger .
Learning is the process of minimizing loss function, finally find out the right weights and biases:
- Early stopping.
- Dropout.
- Regularization.
- New activation function.
- Adaptive learning rate.
Gradient Descent
通过梯度下降算法, 优化损失函数, 使其最小化 (沿梯度下降方向, 调整 W 和 B):
其中, 为学习率, 为损失函数, 为损失函数的梯度, 为模型参数, 为迭代次数.

def convex_function(x):
return x**2
def gradient_descent(initial_x, learning_rate, num_iterations):
x_values = [initial_x]
y_values = [convex_function(initial_x)]
x = initial_x
for i in range(num_iterations):
gradient = 2 * x # 函数 f(x) = x^2 的导数为 f'(x) = 2x
x -= learning_rate * gradient
x_values.append(x)
y_values.append(convex_function(x))
return x_values, y_values
Gradient
一个优秀的梯度下降算法, 需要满足以下几个条件:
- 高效性: 梯度下降算法的迭代次数尽可能少. 当距离最小值较远时, , 当距离最小值较近时, , 这样的梯度下降算法可以更快地收敛. 反之, 当距离最小值较远时, , 这样的梯度下降算法更慢收敛.
- 稳定性: 梯度下降算法的迭代过程尽可能稳定. Maxout 激活函数拟合能力非常强, 可以拟合任意的凸函数.
- 鲁棒性:
梯度下降算法对于
初始值的选择或者特定的线索片段不敏感. Dropout 策略 减少神经元之间复杂的共适应关系 (每个神经元有 概率不被激活), 迫使网络去学习更加鲁棒的特征, 缓解过拟合问题, 提高模型的泛化能力.
Learning Rate
必要时需要调整学习率, 使得梯度下降更快收敛:
- 如果学习率过大, 可能会导致梯度下降不稳定, 甚至发散.
- 如果学习率过小, 可能会导致梯度下降收敛速度过慢.
常见的学习率调整策略有:
- Learning rate decay:
- 阶梯衰减 (Step Decay): .
- 线性衰减 (Linear Decay): .
- 指数衰减 (Exponential Decay): .
- 余弦衰减 (Cosine Decay): .
- Warm up learning rate: increase and then decrease learning rate.
- SGD with momentum: .
- Adaptive learning rate:
Critical Point
当遇到 的情况时, 可能是以下几种情况:
- 局部最小值 (Local Minimum).
- 局部最大值 (Local Maximum).
- 鞍点 (Saddle Point).
此时利用泰勒级数展开, 可以得到:
其中, 为 Hessian 矩阵, 为二阶导数矩阵:
- 当 为正定矩阵时, 为局部最小值.
- 当 为负定矩阵时, 为局部最大值.
- 当 为不定矩阵时, 为鞍点.
在高维空间中, 鞍点的数量远远多于局部最小值. 深度神经网络拥有大量的参数, 使得其损失函数的鞍点数量远远多于局部最小值.
Backpropagation
反向传播算法: 从最小化损失函数出发, 由输出层到输入层, 通过链式法则, 计算每一层的梯度, 从而更新权重和偏置.

Derivative chain rule (链式法则):
outcomes
Utilize parallel computing (GPU) to speed up training process:
- Divide training data into mini-batches.
- Update weights and biases for each mini-batch.
- Repeat until convergence.
| Batch Size | Small | Large |
|---|---|---|
| Speed (Sequential) | Faster | Slower |
| Speed (Parallel) | Same | Same |
| One Epoch Time | Slower | Faster |
| Gradient | Noisy | Stable |
| Optimization | Better | Worse |
| Generalization | Better | Worse |

class Network(object):
def SGD(self, training_data, epochs, mini_batch_size, eta, test_data=None):
"""Train the neural network using mini-batch stochastic
gradient descent. The ``training_data`` is a list of tuples
``(x, y)`` representing the training inputs and the desired
outputs. The other non-optional parameters are
self-explanatory. If ``test_data`` is provided then the
network will be evaluated against the test data after each
epoch, and partial progress printed out. This is useful for
tracking progress, but slows things down substantially."""
if test_data:
n_test = len(test_data)
n = len(training_data)
for j in range(epochs):
random.shuffle(training_data)
mini_batches = [
training_data[k : k + mini_batch_size]
for k in range(0, n, mini_batch_size)
]
for mini_batch in mini_batches:
self.update_mini_batch(mini_batch, eta)
if test_data:
print(
"Epoch {0}: {1} / {2}".format(j, self.evaluate(test_data), n_test)
)
else:
print("Epoch {0} complete".format(j))
def update_mini_batch(self, mini_batch, eta):
"""Update the network's weights and biases by applying
gradient descent using backpropagation to a single mini batch.
The ``mini_batch`` is a list of tuples ``(x, y)``, and ``eta``
is the learning rate."""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
for x, y in mini_batch:
delta_nabla_b, delta_nabla_w = self.backpropagation(x, y)
nabla_b = [nb + dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]
nabla_w = [nw + dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]
self.weights = [
w - (eta / len(mini_batch)) * nw for w, nw in zip(self.weights, nabla_w)
]
self.biases = [
b - (eta / len(mini_batch)) * nb for b, nb in zip(self.biases, nabla_b)
]
def backpropagation(self, x, y):
"""Return a tuple ``(nabla_b, nabla_w)`` representing the
gradient for the cost function C_x. ``nabla_b`` and
``nabla_w`` are layer-by-layer lists of numpy arrays, similar
to ``self.biases`` and ``self.weights``."""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
# feedforward
activation = x
activations = [x] # list to store all the activations, layer by layer
zs = [] # list to store all the z vectors, layer by layer
for b, w in zip(self.biases, self.weights):
z = np.dot(w, activation) + b
zs.append(z)
activation = self.non_linearity(z)
activations.append(activation)
# backward pass
delta = self.cost_derivative(activations[-1], y) * self.d_non_linearity(zs[-1])
nabla_b[-1] = delta
nabla_w[-1] = np.dot(delta, activations[-2].transpose())
# Note that the variable l in the loop below is used a little
# differently to the notation in Chapter 2 of the book. Here,
# l = 1 means the last layer of neurons, l = 2 is the
# second-last layer, and so on. It's a renumbering of the
# scheme in the book, used here to take advantage of the fact
# that Python can use negative indices in lists.
for l in range(2, self.num_layers):
z = zs[-l]
sp = self.d_non_linearity(z)
delta = np.dot(self.weights[-l + 1].transpose(), delta) * sp
nabla_b[-l] = delta
nabla_w[-l] = np.dot(delta, activations[-l - 1].transpose())
return (nabla_b, nabla_w)
Convolutional Architecture
Convolution
Convolution is a mathematical operation that combines two functions to produce a third function:
Given and , then: , e.g . 上述计算可以转换为多项式相乘的形式:
可以运用快速傅里叶变换 (FFT) 以 的时间复杂度求解 的值, 从而实现快速卷积运算.
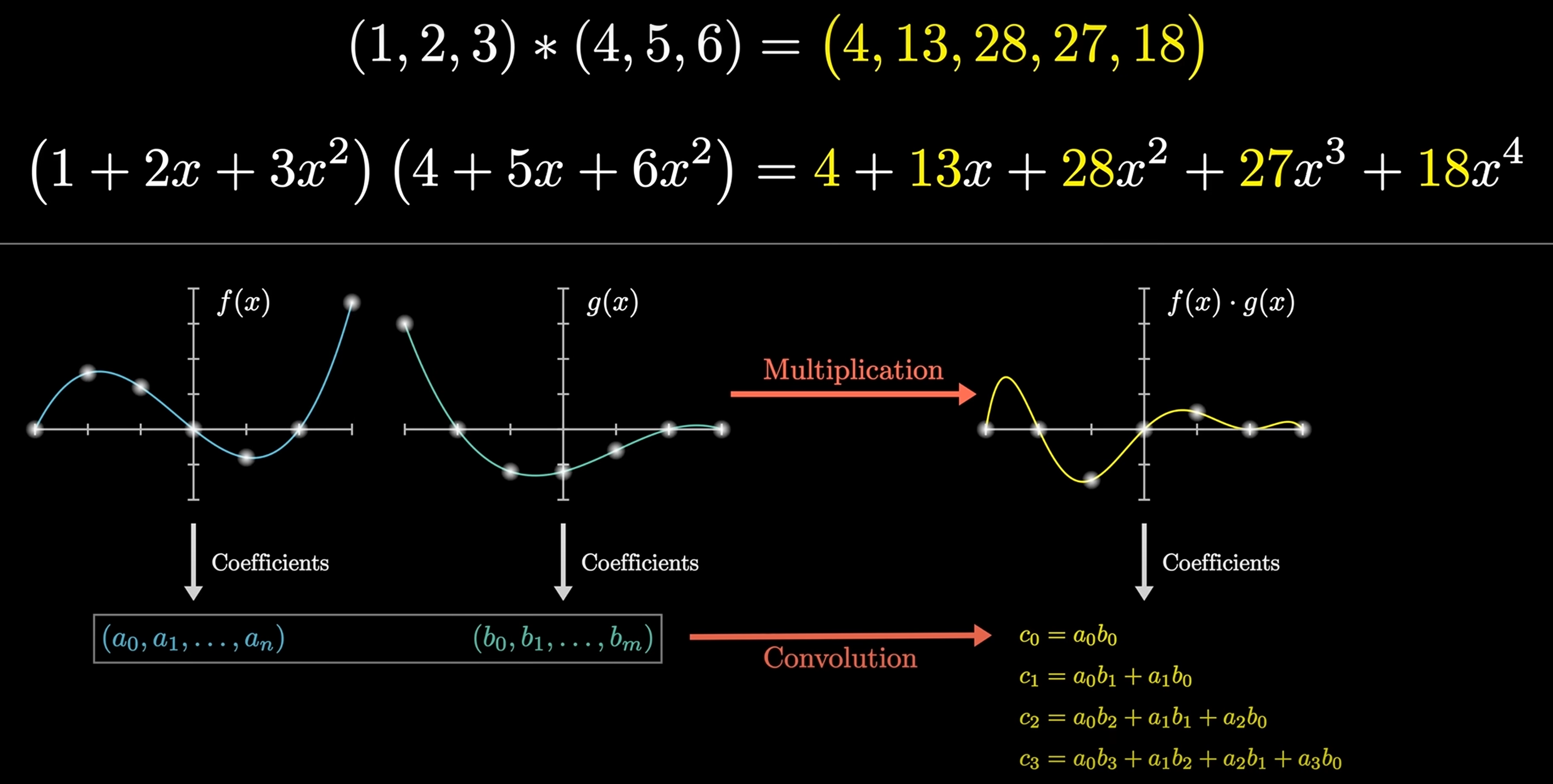
For matrix:
Convolutional Neural Networks
CNNs are a class of deep neural networks, most commonly applied to analyzing visual imagery. They are also known as ConvNets:
- Input Layer (输入层): raw pixel values of an image.
- Hidden Layers (隐藏层):
- Convolutional Layer (卷积层): find patterns in regions of the input, and passing the results to the next layer.
- Pooling Layer (池化层): down-samples the input representation, reducing its dimensionality.
- Fully Connected Layer (全连接层): compute the class scores, resulting in a volume of size , where each of the numbers represents a class.
- Output Layer (输出层): class scores.

# Load the data and split it between train and test sets
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
# Scale images to the [0, 1] range
x_train = x_train.astype("float32") / 255
x_test = x_test.astype("float32") / 255
# Make sure images have shape (28, 28, 1)
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
print("x_train shape:", x_train.shape)
print("y_train shape:", y_train.shape)
print(x_train.shape[0], "train samples")
print(x_test.shape[0], "test samples")
# Model parameters
num_classes = 10
input_shape = (28, 28, 1)
model = keras.Sequential(
[
keras.layers.Input(shape=input_shape),
keras.layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
keras.layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
keras.layers.MaxPooling2D(pool_size=(2, 2)),
keras.layers.Conv2D(128, kernel_size=(3, 3), activation="relu"),
keras.layers.Conv2D(128, kernel_size=(3, 3), activation="relu"),
keras.layers.GlobalAveragePooling2D(),
keras.layers.Dropout(0.5),
keras.layers.Dense(num_classes, activation="softmax"),
]
)
model.compile(
loss=keras.losses.SparseCategoricalCrossEntropy(),
optimizer=keras.optimizers.Adam(learning_rate=1e-3),
metrics=[
keras.metrics.SparseCategoricalAccuracy(name="acc"),
],
)
# Train
batch_size = 128
epochs = 20
callbacks = [
keras.callbacks.ModelCheckpoint(filepath="model_at_epoch_{epoch}.keras"),
keras.callbacks.EarlyStopping(monitor="val_loss", patience=2),
]
model.fit(
x_train,
y_train,
batch_size=batch_size,
epochs=epochs,
validation_split=0.15,
callbacks=callbacks,
)
score = model.evaluate(x_test, y_test, verbose=0)
# Save model
model.save("final_model.keras")
# Predict
predictions = model.predict(x_test)
Convolutional Layer
Convolutional Layer is the first layer to extract features from an input image. The layer's parameters consist of a set of learnable filters (or kernels), which have a small receptive field but extend through full depth of input volume.

Pooling Layer
Pooling Layer is used to reduce the spatial dimensions of the input volume. It helps to reduce the amount of parameters and computation in the network, and hence to also control overfitting.
Fully Connected Layer
Fully Connected Layer is a traditional Multilayer Perceptron (MLP) layer. It is used to compute the class scores, resulting in a volume of size , where each of the numbers represents a class.
Spatial Transformer Networks
传统的池化方式 (Max Pooling/Average Pooling) 所带来卷积网络的位移不变性和旋转不变性只是局部的和固定的, 且池化并不擅长处理其它形式的仿射变换.
Spatial transformer networks (STNs) allow a neural network to learn how to perform spatial transformations on the input image in order to enhance the geometric invariance of the model. STNs 可以学习一种变换, 这种变换可以将仿射变换后的图像进行矫正, 保证 CNNs 在输入图像发生变换时, 仍然能够保持稳定的输出 (可视为总是输入未变换的图像).

Recurrent Architecture
Recurrent Neural Networks
循环神经网络 (RNNs) 是一种具有循环结构的神经网络, 可以处理序列数据, 例如时间序列数据, 自然语言文本等.
当序列数据输入到 RNNs 中时, 每个时间步都会产生一个输出, 并将隐藏状态 (Hidden State) 传递到下一个时间步. 因此, 当改变输入序列的顺序时, RNNs 会产生不同的输出 (Changing sequence order will change output).

Long Short-Term Memory
长短期记忆网络 (LSTM) 是一种特殊的 RNN, 通过引入门控机制 (Gate Mechanism) 来控制信息的流动, 解决了长序列训练过程中的梯度消失和梯度爆炸问题.

Residual Architecture
ResNet 通过残差学习解决了深度网络的退化问题 (深度网络的训练问题), 最短的路, 决定容易优化的程度: 残差连接 (Residual Connection) 可以认为层数是 0. 最长的路, 决定深度网络的能力: 解决了深度网络的训练问题后, 可以做到更深的网络 (100+).
ResNet 通过引入残差连接, 允许网络学习残差映射而不是原始映射. 残差映射就是目标层与它的前面某层之间的差异 . 如果输入和输出之间的差异很小, 那么残差网络只需要学习这些微小的差异即可. 这种学习通常比学习原始的复杂映射要简单得多.

从深层网络角度来讲, 不同的层学习的速度差异很大, 表现为网络中靠近输出的层学习的情况很好, 靠近输入的层学习的很慢, 有时甚至训练了很久, 前几层的权值和刚开始随机初始化的值差不多 (无法收敛). 因此, 梯度消失或梯度爆炸的根本原因在于反向传播训练法则, 本质在于方法问题. ResNet 通过残差连接保持梯度传播, 使得网络的训练更加容易:
Transformer Architecture
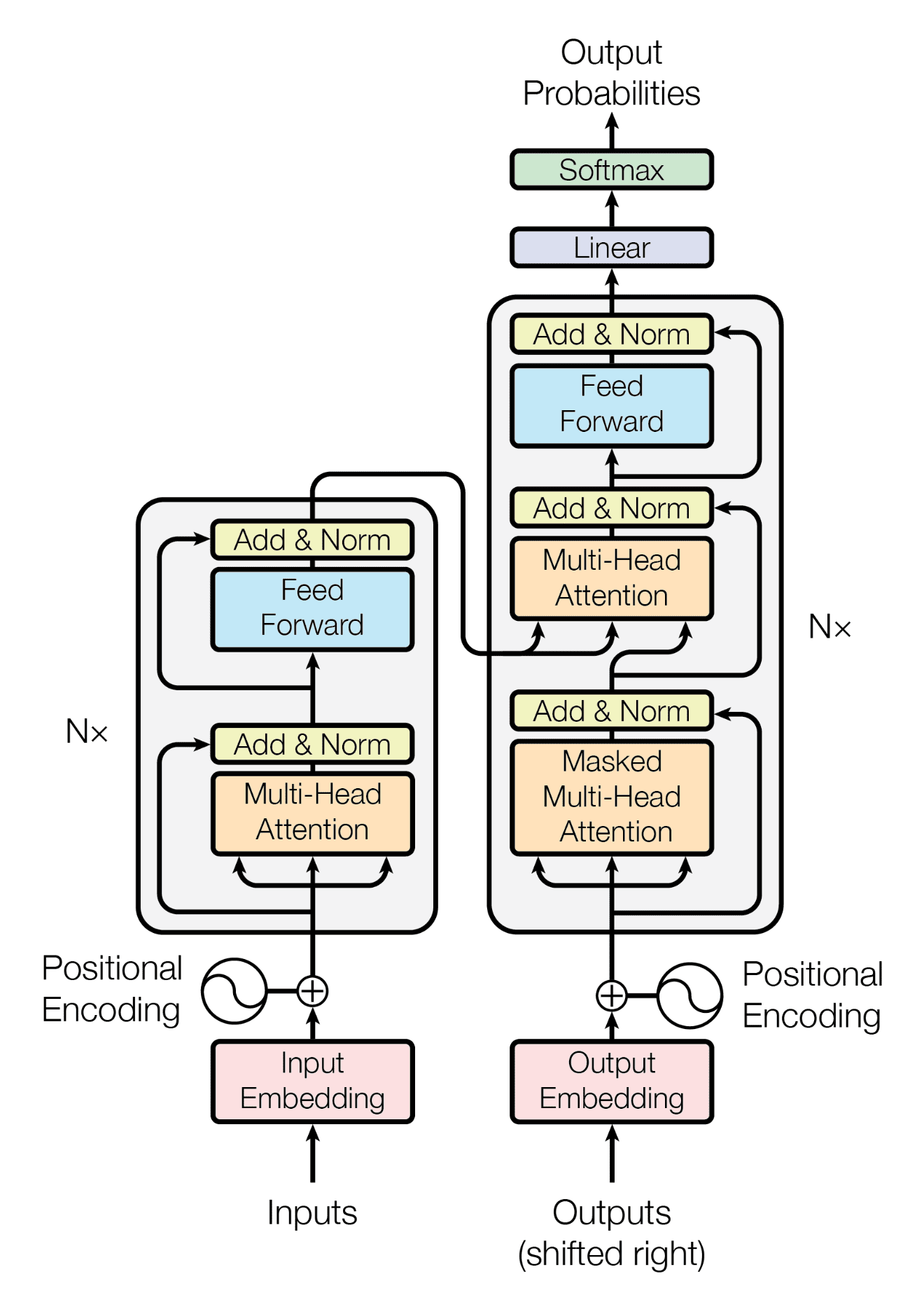
- Self-attention only: comparing to Recurrent Neural Networks (RNNs), no recurrent layers, allows for more parallelization.
- Multi-headed attention: consistent with Convolutional Neural Networks (CNNs), multiple output channels.
Self-Attention Mechanism
In layman's terms, a self-attention module takes in n inputs and returns n outputs:
- Self: allows the inputs to interact with each other
- Attention: find out who they should pay more attention to.
- The outputs are aggregates of these interactions and attention scores.

The illustrations are divided into the following steps:
- Prepare inputs.
- Weights initialization (Constant/Random/Xavier/Kaiming Initialization).
- Derive query, key and value.
- Calculate attention scores for input.
- Calculate softmax.
- Multiply scores with values.
- Sum weighted values to get output.
Weights for query, key and value (these weights are usually small numbers, initialized randomly using an appropriate random distribution like Gaussian, Xavier and Kaiming distributions):
Derive query, key and value:
Calculate attention scores for input:
为行向量分别与自己和其他两个行向量做内积 (点乘), 向量的内积表征两个向量的夹角 (), 表征一个向量在另一个向量上的投影, 投影的值大, 说明两个向量相关度高 (Relevance/Similarity).
Softmaxed attention scores :
softmax function:
其中, 为温度参数 (Temperature Parameter),
用于控制 softmax 函数的输出分布的陡峭程度:
- 时,
softmax函数退化为标准形式. - 时,
softmax函数输出分布更加平缓. - 时,
softmax函数输出分布更加陡峭. - 时,
softmax函数退化为argmax函数, 输出分布中只有一个元素为 1, 其他元素为 0.
矩阵 中每一个元素除以 后, 方差变为 1. 这使得 的分布"陡峭"程度与 解耦, 从而使得训练过程中梯度值保持稳定.
Alignment vectors (yellow vectors) addition to output:
Repeat for every input:
Calculate by matrix multiplication:
Self-attention 中的 思想,
另一个层面是想要构建一个具有全局语义 (Context) 整合功能的数据库,
使得 Context Size 内的每个元素都能够看到其他元素的信息,
从而能够更好地进行决策.
import torch
from torch.nn.functional import softmax
# 1. Prepare inputs
x = [
[1, 0, 1, 0], # Input 1
[0, 2, 0, 2], # Input 2
[1, 1, 1, 1], # Input 3
]
x = torch.tensor(x, dtype=torch.float32)
# 2. Weights initialization
w_query = [
[1, 0, 1],
[1, 0, 0],
[0, 0, 1],
[0, 1, 1],
]
w_key = [
[0, 0, 1],
[1, 1, 0],
[0, 1, 0],
[1, 1, 0],
]
w_value = [
[0, 2, 0],
[0, 3, 0],
[1, 0, 3],
[1, 1, 0],
]
w_query = torch.tensor(w_query, dtype=torch.float32)
w_key = torch.tensor(w_key, dtype=torch.float32)
w_value = torch.tensor(w_value, dtype=torch.float32)
# 3. Derive query, key and value
queries = x @ w_query
keys = x @ w_key
values = x @ w_value
# 4. Calculate attention scores
attn_scores = queries @ keys.T
# 5. Calculate softmax
attn_scores_softmax = softmax(attn_scores, dim=-1)
# tensor([[6.3379e-02, 4.6831e-01, 4.6831e-01],
# [6.0337e-06, 9.8201e-01, 1.7986e-02],
# [2.9539e-04, 8.8054e-01, 1.1917e-01]])
# For readability, approximate the above as follows
attn_scores_softmax = [
[0.0, 0.5, 0.5],
[0.0, 1.0, 0.0],
[0.0, 0.9, 0.1],
]
attn_scores_softmax = torch.tensor(attn_scores_softmax)
# 6. Multiply scores with values
weighted_values = values[:, None] * attn_scores_softmax.T[:, :, None]
# 7. Sum weighted values
outputs = weighted_values.sum(dim=0)
print(outputs)
# tensor([[2.0000, 7.0000, 1.5000],
# [2.0000, 8.0000, 0.0000],
# [2.0000, 7.8000, 0.3000]])
# tensor([[1.9366, 6.6831, 1.5951],
# [2.0000, 7.9640, 0.0540],
# [1.9997, 7.7599, 0.3584]])
自注意力机制能够直接建模序列中任意两个位置之间的关系, 进而有效捕获长程依赖关系, 具有更强的序列建模能力. 自注意力的计算过程对于基于硬件的并行优化 (GPU/TPU) 非常友好, 因此能够支持大规模参数的高效优化.
Multi-Head Attention Mechanism
Multiple output channels:
from math import sqrt
import torch
import torch.nn
class Self_Attention(nn.Module):
# input : batch_size * seq_len * input_dim
# q : batch_size * input_dim * dim_k
# k : batch_size * input_dim * dim_k
# v : batch_size * input_dim * dim_v
def __init__(self, input_dim, dim_k, dim_v):
super(Self_Attention, self).__init__()
self.q = nn.Linear(input_dim, dim_k)
self.k = nn.Linear(input_dim, dim_k)
self.v = nn.Linear(input_dim, dim_v)
self._norm_fact = 1 / sqrt(dim_k)
def forward(self, x):
Q = self.q(x) # Q: batch_size * seq_len * dim_k
K = self.k(x) # K: batch_size * seq_len * dim_k
V = self.v(x) # V: batch_size * seq_len * dim_v
# Q * K.T() # batch_size * seq_len * seq_len
attention = nn.Softmax(dim=-1)(torch.bmm(Q, K.permute(0, 2, 1))) * self._norm_fact
# Q * K.T() * V # batch_size * seq_len * dim_v
output = torch.bmm(attention, V)
return output
class Self_Attention_Multiple_Head(nn.Module):
# input : batch_size * seq_len * input_dim
# q : batch_size * input_dim * dim_k
# k : batch_size * input_dim * dim_k
# v : batch_size * input_dim * dim_v
def __init__(self, input_dim, dim_k, dim_v, nums_head):
super(Self_Attention_Multiple_Head, self).__init__()
assert dim_k % nums_head == 0
assert dim_v % nums_head == 0
self.q = nn.Linear(input_dim, dim_k)
self.k = nn.Linear(input_dim, dim_k)
self.v = nn.Linear(input_dim, dim_v)
self.nums_head = nums_head
self.dim_k = dim_k
self.dim_v = dim_v
self._norm_fact = 1 / sqrt(dim_k)
def forward(self, x):
Q = self.q(x).reshape(-1, x.shape[0], x.shape[1], self.dim_k // self.nums_head)
K = self.k(x).reshape(-1, x.shape[0], x.shape[1], self.dim_k // self.nums_head)
V = self.v(x).reshape(-1, x.shape[0], x.shape[1], self.dim_v // self.nums_head)
print(x.shape)
print(Q.size())
# Q * K.T() # batch_size * seq_len * seq_len
attention = nn.Softmax(dim=-1)(torch.matmul(Q, K.permute(0, 1, 3, 2)))
# Q * K.T() * V # batch_size * seq_len * dim_v
output = torch.matmul(attention, V).reshape(x.shape[0], x.shape[1], -1)
return output
Positional Encoding Mechanism
位置编码 使用正弦和余弦函数的 d 维向量编码方法, 用于在输入序列中表示每个单词的位置信息, 丰富了模型的输入数据, 为其提供位置信息 (把词序信号加到词向量上帮助模型学习这些信息):
- 唯一性 (Unique): 为每个时间步输出一个独一无二的编码.
- 一致性 (Consistent): 不同长度的句子之间, 任何两个时间步之间的距离保持一致.
- 泛化性 (Generalizable): 模型能毫不费力地泛化到更长的句子, 位置编码的值是有界的.
- 确定性 (Deterministic): 位置编码的值是确定性的.
编码函数使用正弦和余弦函数, 其频率沿着向量维度进行减少. 编码向量包含每个频率的正弦和余弦对, 以实现 和 的线性变换, 从而有效地表示相对位置.
For (where ), then
where
outcomes
KV Cache
Prompt caching
缓存的不是文本是思维状态, 本质是复用 KV 矩阵.
Explainable AI
Local Explanation
Explain the decision of a single instance
(why do you think this image is a cat):
- Saliency map: use gradient to highlight most important pixels for model's decision .
- Probing: perturb input and observe how prediction changes (via 3rd NNs).
Global Explanation
Explain the whole model
(what does a cat look like).