Large Language Model
Generative Model
- Autoregressive (AR) model: generate output one token at a time, conditioned on previous tokens.
- Non-autoregressive (NAR) model: generate output all at once parallel, without conditioning on previous tokens.
| AR Model | NAR Model | |
|---|---|---|
| Parallelism | Low | High |
| Speed | Slow | Fast |
| Quality | High | Low |
结合上述两种方法 (Encoder + Decoder 架构):
- 用 AR model 生成中间向量, 用 NAR model 生成最终输出.
- 用 NAR model 多次生成, 逐步优化输出.
- Speculative decoding: 用 NAR model 快速生成若干个预测输出, 作为 AR model 的后续输入, 使得 AR model 可以同时输出多个结果.

ChatGPT
Fine-tuned GPT model on conversational data:
- Pre-training: 学习文字接龙, 学习大规模资料 (self-supervised learning), 生成下一个单词.
- Instruction-tuning (IT): 人工文字接龙, 人工标注部分问题的答案 (supervised learning), 引导模型生成的方向.
- Reinforcement learning from human feedback (RLHF): 训练一个 reward model, 负责评价模型生成的答案, 提供人类反馈. 以 reward model 的评价分数为 reward, 通过强化学习优化模型. 一般聚焦于三个方面: 有用性 (Helpfulness), 诚实性 (Honesty), 无害性 (Harmlessness).
Instruction-tuning (IT) with supervised learning on labelled data and reinforcement learning from human feedback (RLHF).
Diffusion
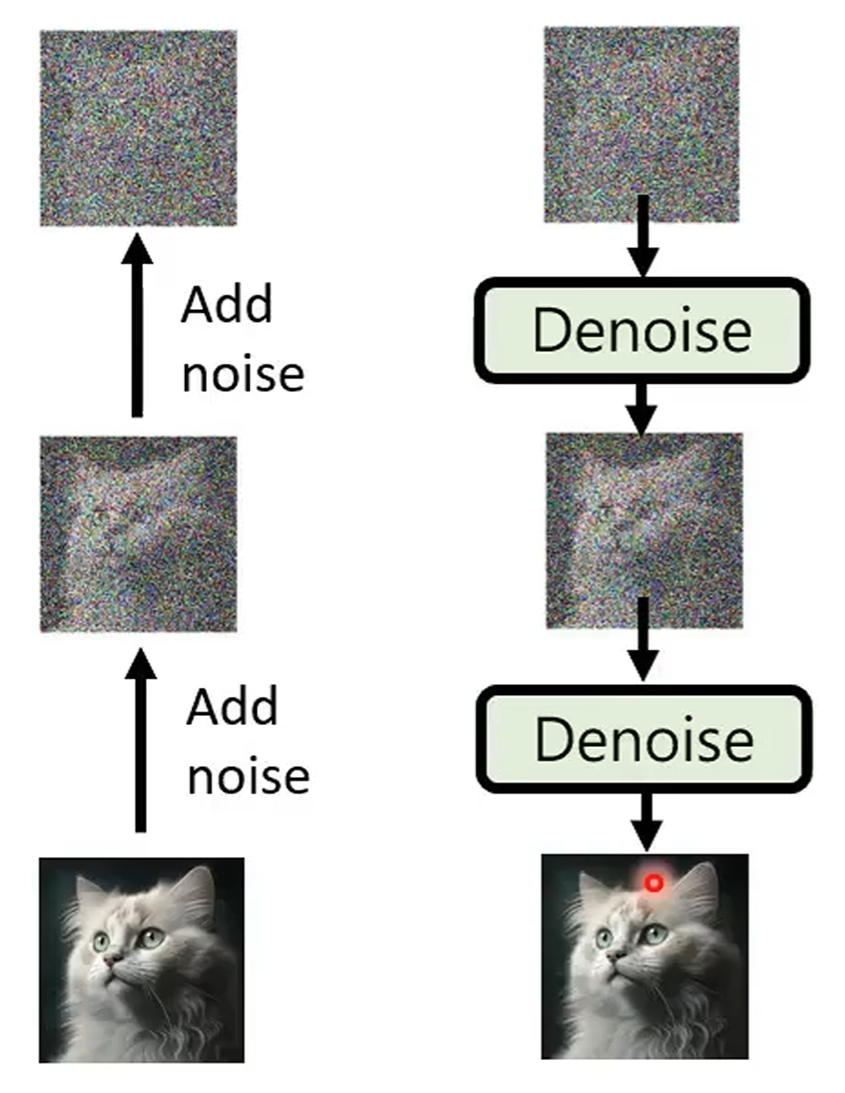
Forward process (diffusion) + reverse process (denoise):
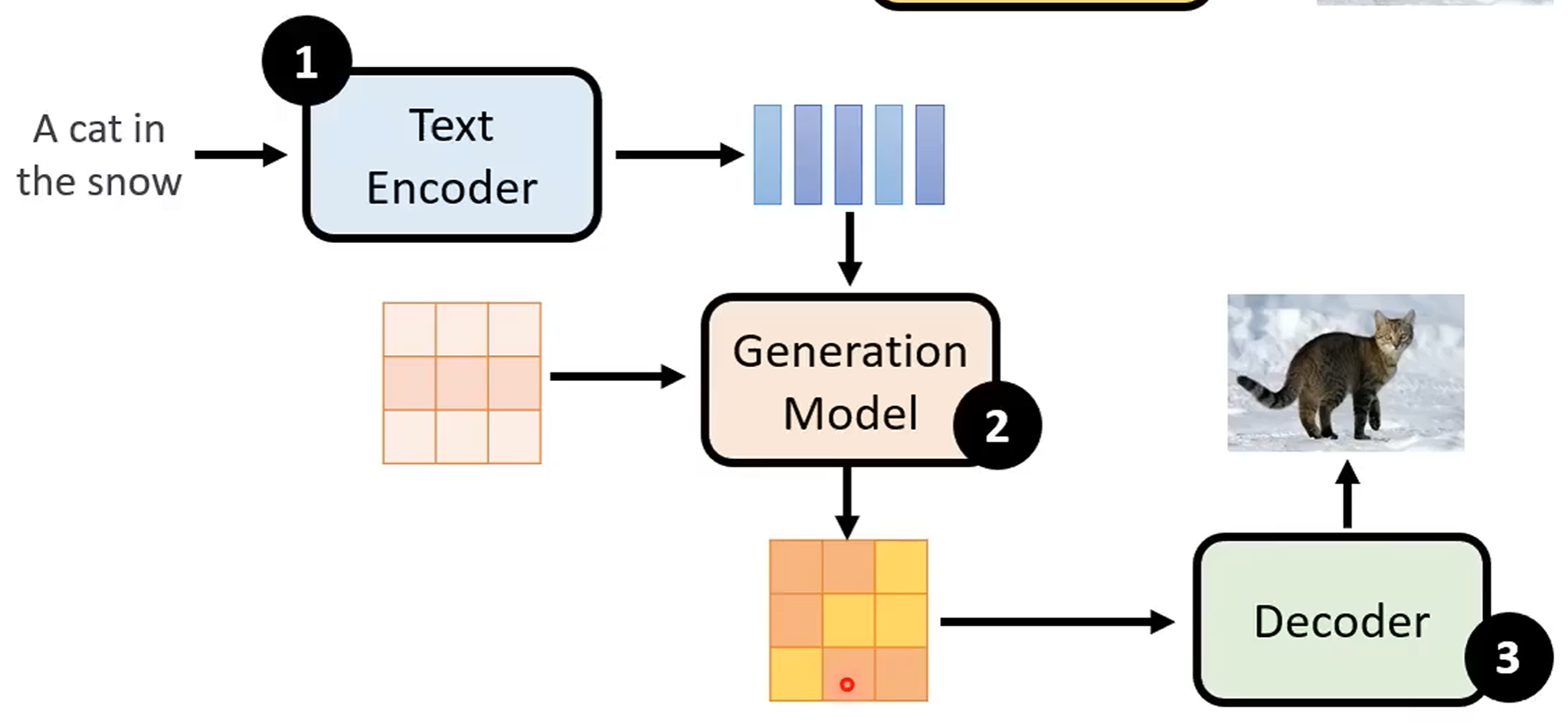
Stable diffusion model:
Video
Generative videos as world models simulator.
Embeddings
- Continuous bag of words (CBOW): Predict middle word, with embeddings of surrounding words as input. Fast to train and accurate for frequent words.
- Skip-gram: predict surrounding words in certain range, with middle word as input. Slower to train but accurate for rare words.
- GloVe/SWIVEL: Capture both global and local information about words with co-occurrence matrix.
- Shallow BoW.
- Deeper pre-trained.
- Multi-modal: image.
- Structured data.
- Graph.


Maps two sets of data (user dataset, item/product/etc dataset) into the same embedding space.
Embeddings + ANN (approximate nearest neighbor) vector stores (ScaNN, FAISS, LSH, KD-Tree, and Ball-tree):
- Retrieval augmented generation (RAG).
- Semantic text similarity.
- Few shot classification.
- Clustering.
- Recommendation systems.
- Anomaly detection.

Group Relative Policy Optimization
- GRPO tricks.
Inference Acceleration
- Quantization: 改变模型权重和激活值的精度.
- Distillation: data, knowledge, on policy.
- Flash attention: minimize data move between slow HBM to faster memory tier (SRAM/VMEM).
- Prefix caching: avoid recalculating attention scores for input on each auto-regressive decode step.
- Speculative decoding: generate multiple candidates with drafter model (much smaller).
- Batching and parallelization: sequence, pipeline, tensor.
Reasoning
Test-time compute (inference-time compute): prompting models to generate intermediate reasoning steps dramatically improved performance on hard problems.
Thinking tokens are model's only persistent memory during reasoning.
Retrieval-Augmented Generation
检索增强生成, 通常称为 RAG (Retrieval-Augmented Generation), 是一种强大的聊天机器人的设计模式. 其中, 检索系统实时获取与查询相关的经过验证的源 / 文档, 并将其输入生成模型 (例如 GPT-4) 以生成响应:
- Effect: reduce hallucination.
- Cost: avoid retraining.

Context
Context is everything when it comes to getting the most out of an AI tool. To improve the relevance and quality of a generative AI output, you need to improve the relevance and quality of the input.
Agentic
Agentic RAG (autonomous retrieval agents) actively refine their search based on iterative reasoning:
- Context-aware query expansion.
- Multi-step reasoning.
- Adaptive source selection.
- Validation and correction.
Scaling Law
现有的预训练语言模型对于数据的需求量远高于扩展法则 (e.g. Chinchilla) 中所给出的估计规模. 很多更小的模型也能够通过使用超大规模的预训练数据获得较大的模型性能提升. 这种现象的一个重要原因是由于 Transformer 架构具有较好的数据扩展性. 目前为止, 还没有实验能够有效验证特定参数规模语言模型的饱和数据规模 (即随着数据规模的扩展, 模型性能不再提升).
Emergent Ability
大语言模型的涌现能力被非形式化定义为
在小型模型中不存在但在大模型中出现的能力:
- In-context learning.
- Instruction following.
- Step-by-step reasoning.
Recursive Language Models
RLM
通过分治与递归, 实现多跳推理代码, 解决长文本带来的 Context Rot 问题.
Library
Embeddings and Vector Stores
- OpenCLIP: Encodes images and text into numerical vectors.
- Chroma: AI-native embedding database.
- FaISS: Similarity searching and dense vectors clustering library.
Text-to-Speech
- MiniMax: MiniMax voice agent.
- ChatTTS: Generative speech model for daily dialogue.
- ChatterBox: SoTA open-source TTS model.
LLMs
- OLlama: Get up and running large language models locally.
- OLlamaUI: User-friendly web UI for LLMs.
- Transformers: Run HuggingFace transformers directly in browser.
- Jan: Offline local ChatGPT.
- LocalLLMs: Curated list of locally running LLMs.
References
- 大语言模型综述.
- Efficient LLM architectures survey.
- Foundational LLM whitepaper.