Context
注意力计算复杂度是 , 且是稀疏的 (模型不会均匀地关注所有输入):
- 上下文窗口受硬件边界限制.
- 有效上下文小于标称上下文: coding agent 只能有效利用其中的 10-15 .
Lost in the middle: 中间内容容易被忽略, 更关注开头和结尾.
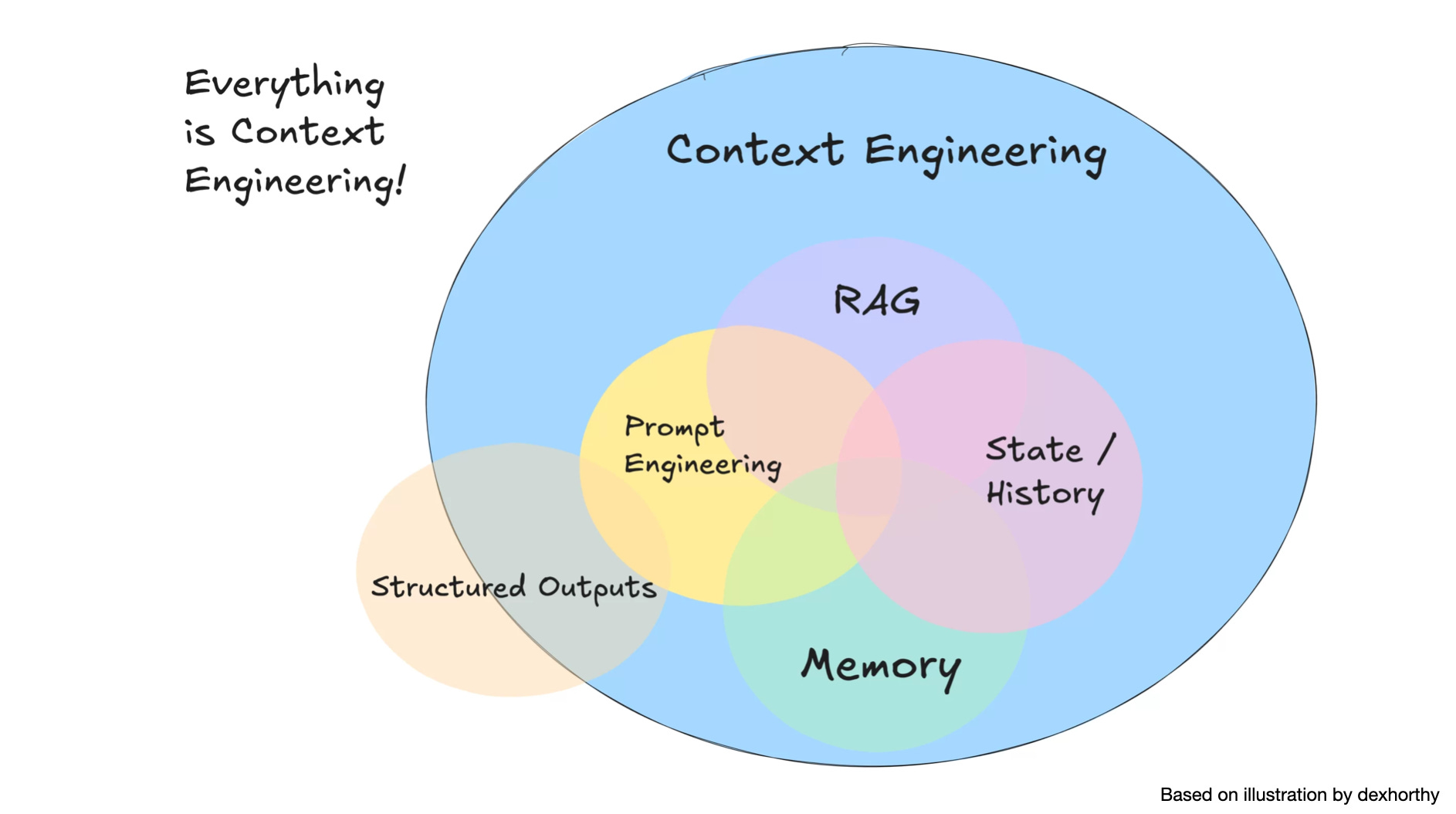
Engineering
LLM 并未统一利用其上下文,
它们的准确性和可靠性会随着输入令牌数量的增加而下降,
称之为上下文腐烂 (Context Rot).
因此, 仅仅在模型的上下文中拥有相关信息是不够的:
信息的呈现方式对性能有显著影响.
这凸显了 上下文工程 的必要性,
优化相关信息的数量并最小化不相关上下文以实现可靠的性能.
e.g. custom gemini CLI command.
Planning with Files
- Design around KV-cache:
- 稳定内容放前面: system prompt, tool definitions.
- 动态内容放后面: chat history, user input.
- 避免在稳定前缀中插入可变内容: e.g. 禁止在 system prompt 中插入时间戳.
- Plan is required
- Files are memory
- Don't get few-shotted: get rid of repetitive actions
- Manipulate attention through recitation
Start of context: [Original goal - far away, forgotten]
...many tool calls...
End of context: [Recently read task_plan.md - gets ATTENTION!]
Dynamic Discovery
Dynamic context discovery:
- 工具响应 -> 文件.
- 终端会话 -> 文件.
- 上下文压缩时引用对话历史.
- 按需加载.
- 渐进式披露.
Personalization
Meta-prompting for memory extraction:
You are a [USE CASE] agent whose goal is [GOAL].
What information would be important to keep in working memory during a single session?
List both fixed attributes (always needed) and inferred attributes (derived from user behavior or context).
Memory System
- Repeatable memory loop: inject → reason → distill → consolidate.
- Enforce precedence: current user message > session context > memory.