若随机变量 X 服从一个位置参数为 μ, 尺度参数为 σ 的概率分布,
且其概率密度函数 (Probability Density Function, PDF) 为:
f(x)=σ2π1e−21(σx−μ)2
则这个随机变量称为正态随机变量, 正态随机变量服从的分布称为正态分布,
记作 X∼N(μ,σ2), 读作 X 服从 N(μ,σ2) (正态分布).
其中 μ 为均值 (数学期望 Mean), σ 为标准差 (Standard Deviation).
正态分布 (又称 Gaussian Distribution) 是一种连续概率分布.
当 μ 为 0, σ 为 1 时, 称为标准正态分布 (Standard Normal Distribution).
在自然界与生产中, 一些现象受到许多相互独立的随机因素的影响,
如果每个因素所产生的影响都很微小时, 总影响 (Sum) 可以看作服从正态分布.
相互独立的正态分布, 其和也是正态分布.
总体正态分布的均值等于各个分布的均值之和,
E(X1+⋯+Xn)=E(X1)+⋯+E(Xn)=nμ.
假设协方差为 0, 则总体正态分布的方差等于各个分布的方差之和,
Var(X1+⋯+Xn)=Var(X1)+⋯+Var(Xn)=nσ2,
可以得到总体正态分布的标准差为 nσ.
设随机变量 X1,X2,…,Xn 独立同分布(Independent Identically Distribution),
且均值为 E(Xi)=μ, 方差为 D(Xi)=σ2,
对于任意 x, 其分布函数为
Fn(x)=P{nσ∑i=1nXi−nμ≤x}
满足
n→∞limFn(x)=n→∞limP{nσ∑i=1nXi−nμ≤x}=2π1∫−∞xe−2t2dt=∅(x)
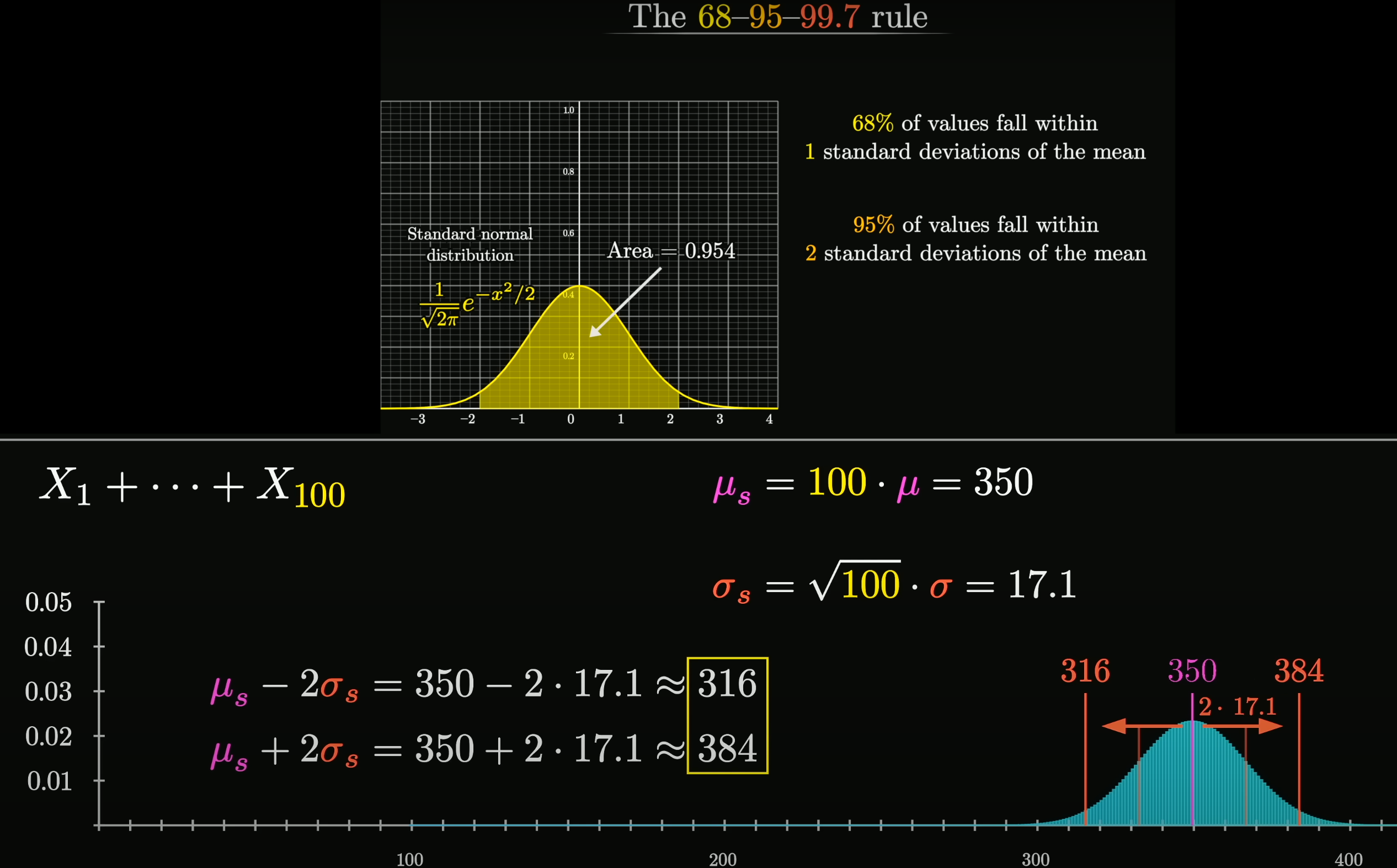
独立同分布的中心极限定理说明, 当 n 足够大时,
随机变量 Xn=i=1∑nXi
近似服从正态分布 N(nμ,nσ2);
标准化后的随机变量 Yn=nσ∑i=1nXi−nμ
近似服从标准正态分布 N(0,1).
更一般化的中心极限定理,
可参见林德伯格中心极限定理 (Lindeberg CLT)
etc.
∫−∞∞e−x2dx=π
高维空间求解高斯积分:
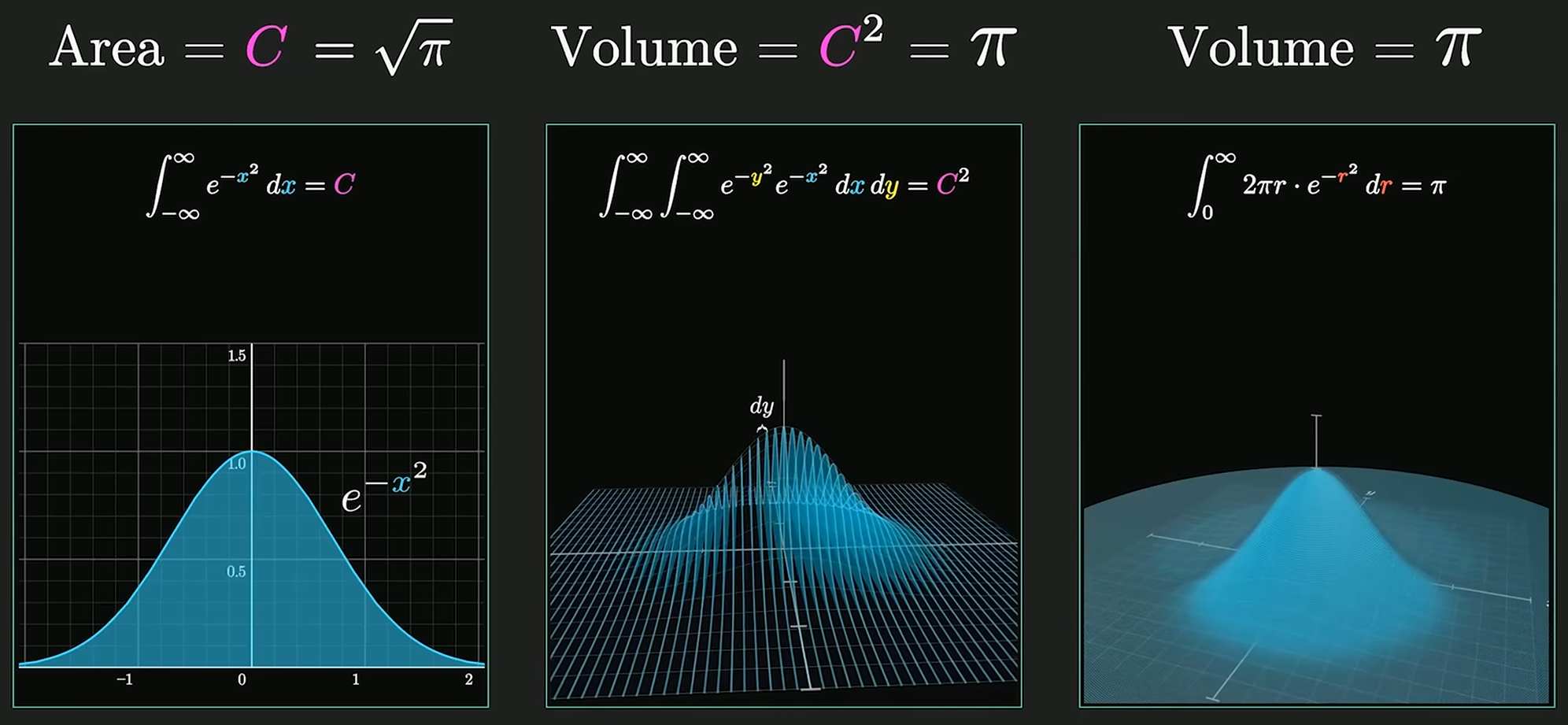
对于正态分布, 系数 π1 使得概率密度函数的积分为 1,
即 ∫−∞∞f(x)dx=1, 使其成为有意义的概率分布.
重复 n 次独立的伯努利试验, X∼B(n,p), 期望值 E(X)=np, 方差 D(X)=np(1−p):
P(X=k)=Cnkpk(1−p)n−k
Bayes theorem:
P(A∩B)=P(A∣B)P(B)=P(B∣A)P(A)⇒
P(A∣B)=P(B)P(B∣A)P(A)=P(B∣A)P(A)+P(B∣¬A)P(¬A)P(B∣A)P(A)

其中, P(B∣¬A)P(B∣A) 称为贝叶斯系数 (Bayes Factor):
O(A∣B)=P(¬A∣B)P(A∣B)=P(¬A∣B)P(B)P(A∣B)P(B)=P(B∣¬A)P(¬A)P(B∣A)P(A)=O(A)P(B∣¬A)P(B∣A)
信息熵
是对信息量的度量 (E[I]),
概率小的事件发生所带来的信息量大, 概率大的事件发生所带来的信息量小,
即概率小, 出现机会小, 不确定性大, 信息熵大, 信息量大:
H(X)=E[−log2P(xi)]=−i=1∑nP(xi)log2P(xi)